So, we (TimandAnton, the crew behindthe podcast) wanted to post another reflections blog based on ourCloud Security Podcast by Googlebeing almost 3 (we will be 3 years old on Feb 11, 2024, to be precise), kind of similar tothis one. But we realized we don’t have enough new profound reflections…. We do have a few fun new things!
So, what did we do differently in 2023?
We started doing the LIVE VIDEO recording sessions (the latest)
We also covered a lot of AI... what a NOT surprise 🙂 Let’s go and reflect on that! So we have covered AI for security, we have covered securing AI and we have not yet covered the third pillar (countering the AI-armed attacker).
As a side note, Google Cloud also published SAIF and two exciting papers on AI security and somefun blogs. AI of course will continue to be in our coverage, and a “fun” new episode on AI governance is coming soon (How about that? FUN and GOVERNANCE in the same sentence!).
Overall, here is how word cloud of our 2023 episode titles looks like:
Fun Q1 2024 episodes include cloud detection and response (CDR), cloud forensics, some geopolitics (yes, really, we promise it will be cloudy!) and some classics like cloud migration security woes.
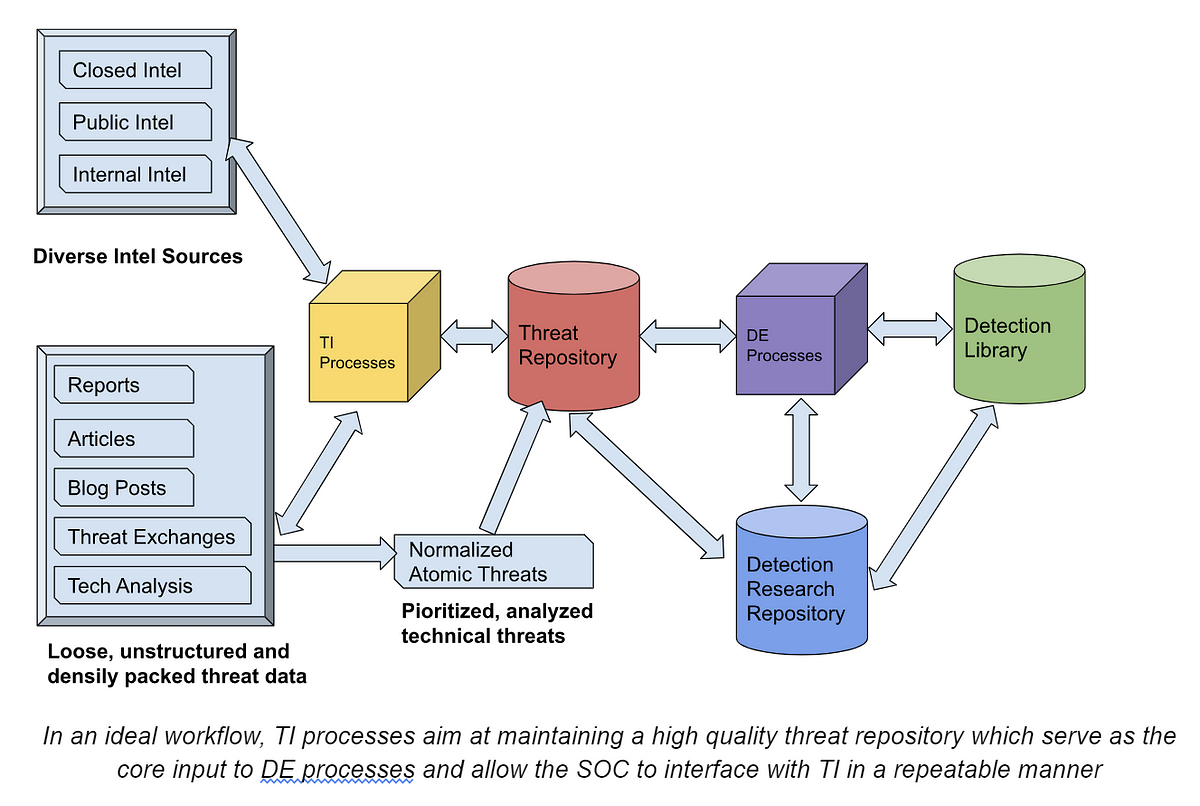
In this blog (#6 in the series), we will covers some DOs and DON’Ts regarding TI/CTI and DE interaction and continue building the TI -> DE process machinery
Threat intelligence (TI / CTI), is a crucial component of cybersecurity, combining elements of art and science to track and understand real-world adversarial operations. While some instances of TI might be driven by research interests or executive curiosity, its primary purpose lies in empowering cyber defenders with usable insights. TI serves as a key input for detection engineering (DE), the team that directly benefits from its findings.
Detections are primarily shaped by intrusion and compromise opportunities (as well as telemetry, of course), which are heavily influenced by intelligence. This intelligence can be derived directly from TI feeds or from red team exercises or threat hunting activities. In turn, these activities benefit from continuous updates to their knowledge base, ensuring they remain effective against evolving threat tactics, techniques, and procedures (TTPs).
In essence, TI plays a pivotal role in bridging the gap between understanding and action in the cybersecurity realm. It provides the necessary context and insights for DE teams to effectively design and implement detection mechanisms that safeguard an organization’s valuable assets against evolving cyber threats.
However as explored in our previous posts, the interface between DE and CTI teams is more often than not imperfect, with three big pain points:
TI teams don’t understand what’s expected from them for DE support
TI teams don’t have a clear duty, mandate or responsibility in their output related to DE
TI teams sometimes don’t have capacity to do operational (read: more useful for detection) intel on top of strategic intel
Re-drafting your Target Operating Model for TI is likely going to help re-shaping operations and informing staffing decisions. Furthermore, understanding more precisely what TI should produce as knowledge items toward the DE team, and what type of collaboration is required throughout the detection lifecycle is the more opportunity for improvement.
OK, What does DE expect from Intel?
In most cases, Detection Engineers ask can be summarized up in this way:
Atomic TTPs, which are intel-informed, prioritized, documented, and added to backlog at the speed of incoming intel.
“Atomic TTPs” here means at the level lower than ATT&CK, but without being hyper-specific to IoCs, or malware-specific signatures (Goldilocks approach: more detailed than “registry key editing by attacker” but less detailed that “RunOnce=rundll82.exe”)
An excellent example of Atomic TTPs is the Atomic Red team library by Red Canary, which demonstrates that going a step lower than ATT&CK techniques allows a clearer understanding of threats, and clear directions to the DE team (a clear example is T1098.001).
In an ideal workflow, TI processes aim at maintaining a high quality threat repository which serve as the core input to DE processes and allow the SOC to interface with TI in a repeatable manner
Make It Better: Four Dimensions of DE-Friendly TI
The better the intel, the better the detections. But what is “better” here? When working on creating new detections, a few things stand out as desirable, and those translate as flags for good intel from the DE perspective:
(More) Structured Data: Data exchange must be Repeatable, Standardized, Accessible and Understandable. In today’s landscape, many tools are used and result in unstructured data which almost always has to be translated into another form by DE teams (think loose emails, a DM with a link to an external article, some enterprise wiki page, lengthy report describing dozens of TTPs, a social discussion chain being forwarded as a screenshot, etc). A harsh reality is that many TI teams spend time turning many PDFs into a single, long and less informational PDF (but, hey, with panda pictures?!) which will only be less useful for technical defenders.
Threat intelligence (TI) originates from diverse sources, necessitating a structured approach to enrichment and comparison by TI analysts before integration into the cybersecurity pipeline. The format adopted for this process can vary based on organizational preferences, ranging from a template-based wiki to a meticulously maintained knowledge base, a ticketing system with mandatory fields, or an as-code approach. Regardless of the chosen format, the goal remains consistent: to transform raw intelligence into actionable insights that empower cybersecurity teams.
2. Meaningful, actionable, searchable knowledge: Structured or not, knowledge is only useful if it can be understood by the recipient party. TI teams must be aware of the output they create, and ensure that it doesn’t require comparable skills for interpretation, or further research to be actioned upon.
Prioritization of research can use other frameworks such as ATT&CK, but the intel work must go further, and avoid simply cutting a report into smaller chunk without adding value, or ensuring readability. If data is searchable, it helps avoiding later duplication of work, and improves reprioritization of previously logged threats.
3. Correct breakdown of intel and research: For a DE, little is worse than spending efforts redoing threat research, and discovering that the TI analyst missed a key detail or misread a source. A general indicator of good intel is that it is coherent, readable and relates to other existing cybersecurity concepts without clashing with detection foundational elements.
4. Peer-checked: While all the the above virtue could be performed by a single individual, chances of misinterpretation of incoming external intel, lower quality output or simply genuine mistakes is drastically reduced if 4 eyes principle are applied (ideally with another TI analyst), or in smaller team in collaboration with a DE sitting at the interface with TI, helping to review and document new threats with the TI analyst. After all, the cyber world is human-driven (sorry, AI…)
Please Not Worse: Seven Dimensions of DE-Hostile TI
TI can be a source of much frustration to DE professionals, as it is complex data that often drift into being insufficient, or overly precise to the point of being unusable. It is so essential, but also often done in ways which make it bad input to process — some of those pains as noticed on the field are:
Universal or hyper specific knowledge items: Think of the infamous Pyramid of Pain — if you are told that Valid Accounts, Technique T1078 — Enterprise | MITRE ATT&CK® is a threat, or that hxxp://x4.x0.x4.x56/MSHTML_C7/start.xml was part of a compromise, as a DE you are deadlocked. In the first case you will spend weeks breaking it down into more atomic threats (often using public sources) before starting working on detections, and in the second case the IoC is likely already obsolete. Apart from use for hunting clues or pivots, such intel has limited value for immediate detection.
Little to no tracking: The side effect of having unstructured data flowing into the SOC is that backlogging is inconsistent, and may not be followed up on appropriately. This can be a mess that then evolves into a bigger mess…
Different ways to express information: Going from a human-written (and human-read) report to crafting detection can be a journey — these goals are just not the same. Different perspectives are possible, but they should be resolved into a single statement when flowing to DE, instead of being sent multiple times from different angles and many overlaps, which make further work harder with the possibility to do things twice.
Using assumptions instead of evidence: Defenders sometimes (well, who are we kidding … often) use their previously acquired knowledge or beliefs when reviewing intelligence, and skipping on the details that may differentiate it from existing data. Ensuring that the TI work is backed by references supports making intel better quality.
Bottom-up approach: The most subtle of sins, but very deadly — starting to think of detections instead of thinking of threats when parsing incoming intel. Doing a clear separation of duty is key to ensure detections are created to detect threats, and not some intermediary assumption that will be forgotten over time — and may prove incorrect or insufficient.
Misunderstanding intelligence: It is not that rare that TI analysts produce a knowledge item for DE team which is just off. It can be very subtle (lack of knowledge around key atomic TTPs) to very blatant (misrepresenting the threat sequence described in a report), but in all ways will be detrimental to the DE down the road.
Lack of collaboration: Throwing complex, over-processed intel over the fence is likely going to do more harm than good if there is no handshake with stakeholders that may have a different outlook on the data produced. Working with other security related teams, such as Endpoint Security, Cloud Security, Security Architecture etc. also allows for better prioritization, especially if mitigations are in place already.
Define your Framework
Now that you have a better idea of good and bad intel for DE purposes, the next part is setting up the process. It is important to keep culture and mindset aligned, as it will ensure that even loose processes are directed towards common goals.
The more experienced and talented the team, the easier getting to your target operating model will be, but some pointers that will work in any environment when first setting the TI -> DE workflow:
Start with defining the process interface between DE and TI (procedures, messaging, sprints etc.)
Focus on key incoming intel (important report providers, industry shared data etc.) to avoid getting drowned when setting the process
Define basic workflows (where to share knowledge items, how they are constructed, key fields that should be filled by TI, prioritization etc.)
Start tasking DE with handling the threat item (ticket, wiki page etc.) and providing quick feedback to the TI analyst if they think it is not perfect
Start tracking some easy (but useful) KPIs (how many threats defined by TI, how many detections out of TI inputs, how long to process etc.)
In our next blog post we’ll go even deeper into this machinery.
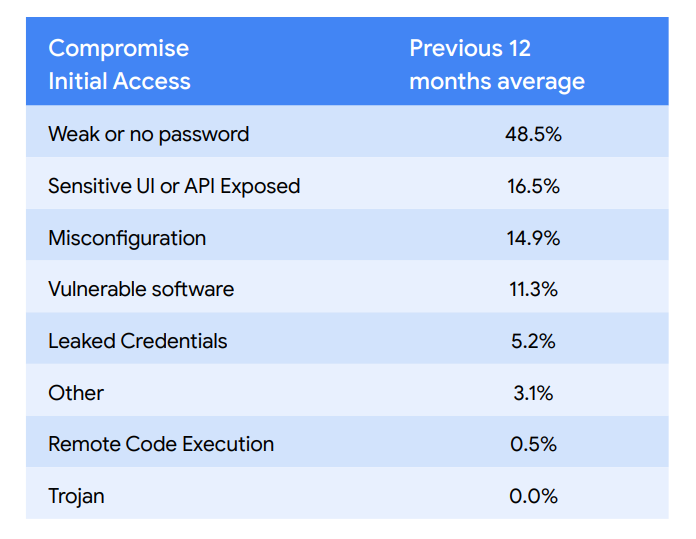
“The cloud compromise factors and outcomes observed in Q2 2023 were largely similar to previous quarters and consistent with the last 12 months of reporting. […] weak credentials continue to represent the largest compromise factor where many observed instances were a result of attackers brute forcing default accounts, Secure Shell (SSH), and the Remote Desktop Protocol (RDP)” [A.C. — as usual, shocking but not surprising. Perhaps the surprise is that it is NOT changing over 2–3 years of ‘clouding’…]
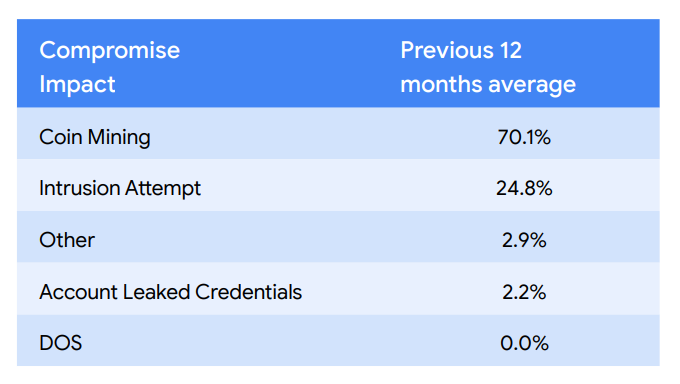
“In the Q2 2022 Threat Horizons Report, we highlight that a disproportionate percentage of attackers opportunistically use coin mining across Cloud products and alter their tactics to evade discovery. This is consistent with this quarter’s findings, as this is the most observed outcome from compromises.” [A.C. -another ‘resilient’ finding, most cloud attackers just cryptomine]
“This quarter our teams observed a 8.5% increase in vulnerable software compromises led primarily by PostgreSQL being the most exploited.” [A.C. — an interesting choice, perhaps some of the instances got ransomed too? Also, I sense this is related to credentials above…]
“SaaS providers were also targeted earlier in the year by suspected financially-motivated DPRK actors in order to gain access to downstream victims.” [A.C. — this is interesting, SaaS as a stepping stone! Is SaaS — likely SaaS credentials, frankly, your weakest link?]
Finally, here is some interesting data focused on healthcare cloud compromises